

Günümüzün veri odaklı ortamında, veri işleme ve analizde performansı ve verimliliği en üst düzeye çıkarmak kritik öneme sahiptir. Birçok Databricks kullanıcısı, makine öğrenimi eğitimi için GPU kümelerini kullanmaya aşina olsa da, veri işleme ve analiz görevleri için de GPU hızlandırmasından yararlanma konusunda büyük bir fırsat var.
Veri tuğlaları' Veri Zekası Platformu, kullanıcılara hem küçük hem de büyük ölçekli veri ihtiyaçlarını verimli bir şekilde yönetme olanağı sağlar. Kullanıcılar, GPU kümelerini mevcut iş akışlarına entegre ederek önemli performans kazanımlarının kilidini açabilir ve analiz yeteneklerini geliştirebilir.
Bu kılavuz, tanıdık API'ler ve eklentilerle veri işlemeyi ve analitiği dönüştürmek için RAPIDS'in Databricks'te GPU hızlandırmanın kilidini açmaya nasıl yardımcı olduğunu araştırıyor. RAPIDS, Databricks kullanıcılarına, tek düğümlü işleme ve Apache Spark ve Dask ile entegrasyon da dahil olmak üzere mevcut iş akışlarını hızlandırmak için birden fazla seçenek sunar. Gönderide, tek düğümlü ve çok düğümlü kullanıcılar için aşağıdaki kurulum seçenekleri ve entegrasyon yöntemleri vurgulanmaktadır.
Tek düğümlü kullanıcılar için RAPIDS, kodda sıfır değişiklikle mevcut pandas iş akışlarını hızlandırabilir. Bu yeni özellik sayesinde, tek düğümlü kullanıcılar artık büyük veri işleme görevleri için RAPIDS cuDF (cuDF) ve pandalar arasında kolayca geçiş yapabilir.
Çok düğümlü kullanıcılar, Apache Spark için RAPIDS hızlandırıcının yanı sıra mevcut Spark kümelerindeki Dask ile iş yüklerini hızlandırabilir.
Apache Spark için RAPIDS hızlandırıcı, Apache Spark 3.0+ sürümünde eklenti olarak mevcuttur. Eklenti, kullanıcıdan herhangi bir kod değişikliği gerektirmeden, Databricks'e SQL ve DataFrame işlemleri için bir RAPIDS arka ucu ekleyerek çalışır. Bir işlem desteklenmiyorsa Spark CPU sürümünün kullanılmasına geri dönülecektir.
Yükleyebilirsiniz Dask Apache Spark ile birlikte kullanın ve aşağıdaki gibi kütüphaneleri kullanın: dask-cudf Çeşitli iş yüklerini verimli bir şekilde ölçeklendirmek için. Dask ve Apache Spark arasındaki farklar, veri işleme iş akışlarınız için en iyi araç kararlarını vermenize yardımcı olmak amacıyla gönderinin ilerleyen kısımlarında özetlenecektir.
Tek düğümlü kullanıcılar: Databricks'te pandaları hızlandırma
pandalar tablo biçiminde yapılandırılmış veriler için popüler bir veri işleme kitaplığıdır. Databricks Runtime, pandaları standart Python paketlerinden biri olarak içerir ve kullanıcıların oluşturmasına ve oluşturmasına olanak tanır. Tek düğümlü bir bilgi işlem ortamında DataFrames ile çalışın.
CuDF Birçok senaryoda pandalara sözdizimsel olarak benzer veya aynı olan, GPU ile hızlandırılmış bir DataFrame kitaplığıdır. RAPIDS v24.02 sürümünden itibaren, cuDF artık pandaların iş akışlarını sıfır kod değişikliğiyle doğrudan hızlandırıyor.
Pandaları hızlandırmak için cuDF kullanma
CuDF pandaları hızlandırdığında, pandas kodu üzerine yazılan tek bir bayrak cudf.pandas'ı çekecektir. Bu kitaplık, pandaları mümkün olduğunda GPU'da çalışacak şekilde otomatik olarak optimize edecek, gerektiğinde geleneksel pandalarla sorunsuz bir şekilde CPU'ya geri dönecek ve senkronizasyon arka planda gerçekleşecek.
Bu yenilikçi yaklaşım, uyumlu bir CPU ve GPU deneyimi sunarak panda iş akışlarınız için en iyi performansı sağlar (Şekil 1).
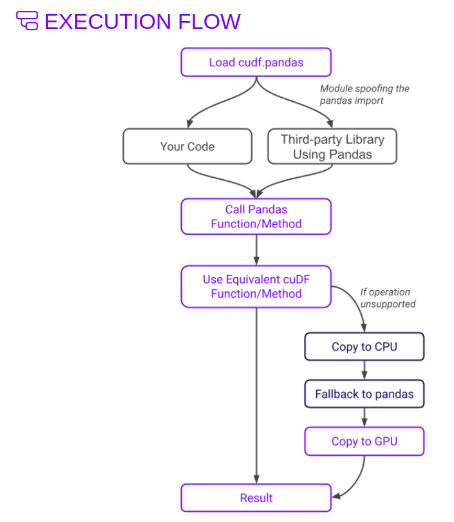
cudf.pandas'ı kullanma Databricks'te tek bir GPU düğümü, büyük veri kümeleriyle uğraşırken geleneksel pandalara göre önemli performans iyileştirmeleri sunabilir. Aşağıdaki genel bakış, cudf.pandas'ın pandalar yavaşladığında onları hızlandırmaya nasıl yardımcı olduğunu açıklamaktadır.
1. Hesaplama hızında en yüksek performans
- panda işlemleri genellikle tek iş parçacıklıdır ve paralellikten yoksundur, özellikle büyük ölçekli veri işleme için modern donanımın hesaplama yeteneklerinden tam olarak yararlanamaz.
- CUDA çerçevesi üzerine inşa edilen cudf.pandas, GPU'ların paralel işlem gücünden yararlanarak filtreleme, toplama ve birleştirme gibi işlemlerin daha hızlı hesaplanmasını sağlar. Bu, özellikle GPU çekirdeklerine dağıtılabilen büyük veri kümeleriyle uğraşırken faydalıdır.
2. Sıfır kod değişikliği hızlandırma
- Kullanıcılar mevcut kodlarındaki cudf.pandas ile pandaları sıfır değişiklikle hızlandırabilirler. Magic komutunu kullanarak cudf.pandas Jupyter Notebook uzantısını yükleyin veya komut satırındaki Python modülü bayrağını kullanın.
| # IPython veya Jupyter Not Defterleri | # Python betiği |
%load_ext cudf.pandas |
python -m cudf.pandas script.py |
3. Birleşik CPU ve GPU iş akışları
- Python paketlerinin büyük çoğunluğu GPU özellikli değildir. Bu, diğer paketleri (PyData kitaplıkları veya kuruluşa özel araçlar) kullanan herhangi bir analiz için kullanıcıların hesaplamayı GPU'dan (cuDF) CPU'ya (pandalar) ve tekrar geri taşıdığı anlamına gelir.
- CuDF pandas hızlandırıcı moduyla artık donanımdan bağımsız olarak tek bir kod yolu ile geliştirme, test etme ve üretimde çalıştırabilirsiniz.
- Üçüncü taraf kitaplık uyumluluğu: cudf.pandas esneklik sunar ve panda nesneleri üzerinde çalışan üçüncü taraf kitaplıkların çoğuyla uyumludur, dolayısıyla bu kitaplıklar içindeki panda işlemlerini hızlandırır.
cuDF pandalar hızlı başlangıç örneği
Pandaları dizüstü bilgisayar ortamında cuDF ile hızlandırmak için talimatları izleyin. tek düğümlü GPU özellikli bir Databricks kümesi başlatın. Daha sonra şunu yükleyin: RAPIDS cuDF pandalarına 10 Dakika not defteri.
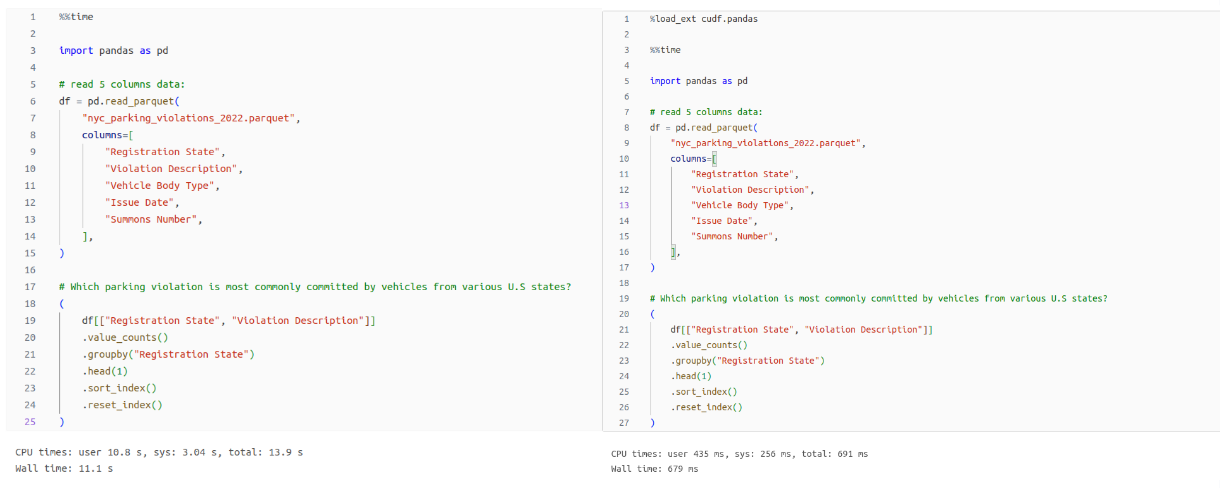
Ayrıca, üçüncü taraf kitaplığın işlevleri içinde çalışan herhangi bir pandas kodu da mümkün olduğu durumlarda GPU hızlandırmasından yararlanacaktır. Örneğin, cudf.pandas'ın pandaların arka ucunu nasıl hızlandırabileceğini gösteren bir resim görebilirsiniz. İbis, çeşitli arka uçlara birleşik bir DataFrame API'si sağlayan bir kitaplık. Bu örnek bir sistemde çalıştırıldı. NVIDIA H100 GPU ve bir Intel Xeon Platinum 8480CL CPU.
cudf.pandas uzantısını yükleyerek, Ibis içindeki panda işlemleri GPU'yu sıfır kod değişikliği ile kullanabilir. Sadece işe yarıyor.

Daha fazla bilgi edinmek için GTC 2024 oturumuna bakın, RAPIDS cuDF Kullanarak Sıfır Kod Değişikliği ile pandaları hızlandırma ve cuDF belgeleri. Ayrıca ilgili yayınlara göz atın, RAPIDS cuDF Sıfır Kod Değişikliğiyle pandaları Neredeyse 150 Kat Hızlandırıyor ve NVIDIA, cuDF pandas Hızlandırıcı Modunu Duyurdu.
Apache Spark ve Dask ile dağıtılmış veri işleme
Apache Spark ve Dask, kullanıcıların daha büyük veri kümeleri için birden fazla işlemcideki iş yüklerini işlemesine yardımcı olan dağıtım çerçeveleridir. Çok düğümlü Databricks kümelerinde Apache Spark ve Dask'tan yararlanmak, GPU kaynaklarının etkili bir şekilde kullanılmasını sağlayarak RAPIDS iş akışları için daha iyi sonuçlara ve genel performansa dönüşür.
Databricks'te, Spark kümeleri, yürütmeyi yöneten bir sürücü düğümü ve paralel görevleri hesaplamak için birden fazla çalışan düğümüyle büyük ölçekli veri işlemede öne çıkıyor. Apache Spark, ETL ve SQL sorguları gibi geleneksel iş zekası iş yüklerinin yanı sıra hafif makine öğrenimine de güçlü bir şekilde odaklanır.
Dask kümeleri, Spark kümeleriyle benzer bir mimariyi paylaşır ancak çeşitli iş yüklerine, özellikle de geleneksel SQL tarzı hesaplamalara daha az odaklananlara uygun, esnek bir paralel bilgi işlem çerçevesi sunar. Örneğin Dask, çok boyutlu dizileri, GIS'i ve gelişmiş makine öğrenimini yönetmede başarılıdır.
Çok Düğümlü Databricks: Apache Spark ile Hızları Hızlandırma
Databricks'te bir Spark kümesi, Apache Spark ile büyük ölçekli veri işlemeyi yönetir ve paralellik elde etmek için iş yüklerini birden fazla düğüme dağıtır.
Databricks'te çok düğümlü bir küme başlattığınızda, bir Spark sürücü düğümü ve birçok Spark çalışan düğümü sağlanır. Sürücü düğümü genel Spark uygulamasının yönetilmesinden sorumludur, çalışan düğümler ise gönderilen görevleri yürütür.
Apache Spark için RAPIDS Hızlandırıcı kullanarak Dataframe ve SQL işlemeyi hızlandırmak için GPU'lardan yararlanan Apache Spark için bir dizi eklenti sağlar. RAPIDS kitaplıkları.
Hızlandırıcı üzerine inşa edilmiştir RAPIDS cuDF projesi Ve UCXve kümedeki her çalışan düğümün CUDA'nın kurulu olmasını gerektirir.
Spark RAPIDS'i bir Databricks kümesiyle kullanmak için kullanıcının bir init senaryo bu indirir rapids-4-spark-xxxx.jar eklentisini seçin ve ardından Spark'ı bu eklentiyi yükleyecek şekilde yapılandırın. Spark sorguları daha sonra libcudf'den yararlanacak ve GPU hızlandırmasından yararlanacaktır.
Apache Spark 3.x için RAPIDS Accelerator'ı Databricks'te kurmak için şu adımları izleyin: Databricks Kullanıcı Kılavuzu. Rehberin sonu şu fırsatı sunuyor: örnek bir Apache Spark uygulaması çalıştırın Databricks'teki NVIDIA GPU'larda çalışır.
Çok Düğümlü Databricks: Dask ile Rapids'i Hızlandırma
Dask PyData ekosistemi boyunca kullanılır ve aşağıdakiler gibi birçok kütüphaneye dahil edilir: X dizisi, ValiRAPIDLER ve XGBoost.
Veri kümeleri ve hesaplamalar CPU'lardan ve RAM'den daha hızlı ölçeklendiğinden, hesaplamaları birden fazla makinede ölçeklendirmenin yollarını bulmak gerekir. Dask, büyük hesaplamaların bölümlenmesine ve dağıtılmış donanıma verimli bir şekilde tahsis edilmesine yardımcı olur.
Neden Databricks'te Dask?
Dask'ın artık bir dask-databricks CLI aracı (başından sonuna kadar konda Ve pip) Databricks'te Dask kümesi başlatma sürecini basitleştirmek için.
Sürücü ve çalışanların Spark kümesi mimarisi Dask kümesiyle aynıdır. bir zamanlayıcısı ve farklı düğümlerde çalışanları olan. Spark RAPIDS örneğinde gösterildiği gibi Databricks, eklentileri yüklemek için başlangıçta her düğümde bir komut dosyası çalıştıracak bir mekanizma sağlar.
Dask on Databricks, başlatma komut dosyası sürecinin bir parçası olarak arka planda bir Dask kümesini önyüklemek için bu paradigmanın avantajından yararlanır. Bu init komut dosyası başlangıçta her düğümde çalışarak gerekli yapılandırmaları ve kurulumları etkinleştirir.
RAPIDS hızlı başlangıç örneği ile Databricks'te Dask
Başlamak için önce bir yapılandırma yapın init Dask'ı, Dask'ı Databricks'e, RAPIDS kitaplıklarına ve diğer tüm bağımlılıklara yüklemek için aşağıdaki içeriklere sahip bir komut dosyası oluşturun.
#!/bin/bash
set -e
# Install RAPIDS (cudf & dask-cudf) and dask-databricks
/databricks/python/bin/pip install --extra-index-url=https://pypi.nvidia.com \
cudf-cu11 \
dask[complete] \
dask-cudf-cu11 \
dask-cuda==24.04 \
Dask-databricks
# Start Dask cluster with CUDA workers
dask databricks run –-cuda
Daha sonra, Databricks not defterinizden bir Dask İstemcisini Spark Sürücü Düğümü üzerinde çalışan zamanlayıcıya hızlı bir şekilde bağlayabilirsiniz.
import dask_databricks
client = dask_databricks.get_client()
Şimdi görevleri kümeye gönderin:
def inc(x):
return x + 1
x = client.submit(inc, 10)
x.result()
Şuraya erişebilirsiniz: Dask kontrol paneli Databricks'i kullanma driver-node vekil. Bağlantı İstemcide veya kullanılarak bulunabilir. client.dashboard_link.
>>> print(client.dashboard_link)
https://dbc-dp-xxxx.cloud.databricks.com/driver-proxy/o/xxxx/xx-xxx-xxxx/8087/status
Daha kapsamlı bir örnek için bkz. Databricks'te XGBoost'u Dask RAPIDS ile eğitmek.
Özet
HIZLILAR En popüler açık kaynaklı veri bilimi araçları gibi görünen ve hisseden API'lere sahip, GPU ile hızlandırılmış Python kitaplıklarından oluşan açık kaynaklı bir pakettir. Bu gönderide, Databricks'teki birleşik ve kullanımı kolay analiz platformunu kullanan RAPIDS'i kullanarak analiz iş yüklerinizi hızlandırmanıza yardımcı olacak birkaç yaklaşım ele alınmıştır:
- Çok düğümlü veri işlemeye yönelik başka bir seçeneği paylaşmaktan heyecan duyuyoruz Dask ve SQL dışı iş yüklerini ölçeklendirmede üstün olan Databricks üzerindeki RAPIDS. Dask desteği artık Databricks'teki mevcut Spark kümelerine entegre edilmiştir.
- Farklı kurulum seçenekleri (cudf.pandas, Spark veya Dask), RAPIDS'i Databricks platformundaki özel ihtiyaçlarınıza uyarlamayı kolaylaştırır.
Veri bilimcileri geleneksel analitiği kullanmaktan yapay zeka uygulamalarından yararlanmaya geçtikçe, geleneksel CPU tabanlı işleme artık hızdan veya maliyetten ödün vermeden buna ayak uyduramaz. Büyük veri analitiğine yönelik artan talep, verileri GPU'larla hızlı bir şekilde işlemek için yeni bir çerçeve ihtiyacını doğurdu.
Sonuç olarak Databricks, GPU hızlandırmayı pandalar ve diğer kitaplıklar ile günlük çalışmanıza sorunsuz bir şekilde entegre etmenizi kolaylaştıran avantajlı bir seçenektir.
Gücünden yararlanıp yararlanmadığınız cudf.pandalar verimli veri manipülasyonu için, Kıvılcım veya Dask Databricks, paralelleştirilmiş bilgi işlem için mevcut RAPIDS iş akışlarınızı GPU özellikleriyle güçlendirmenize olanak tanıyan, yeni performans ve verimlilik düzeylerinin kilidini açan kullanıcı dostu bir ortam sağlar.