
Yapay Zeka, Emoji Uyumlu OCR ve Snapchat'in Ekran Mağazası ile Giyim Alışveriş Deneyimini İyileştirme

Hiç bir fotoğrafta havalı bir gömlek veya benzersiz bir kıyafet giyen birini gördünüz ve onu nereden aldığını merak ettiniz mi? Ne kadara mal oldu? Belki kendinize bir tane almayı bile düşündünüz.
Bu zorluk, Snap'in makine öğrenimi mühendislik ekibine, bir görselde görülen stille eşleşen moda ürünlerini çevrimiçi olarak bulmak ve önermek için yapay zekayı kullanan Snapchat uygulaması içindeki bir hizmet olan Screenshop'u tanıtma konusunda ilham verdi.

Screenshop, 2021 yılında Snapchat uygulamasına entegre edildi. Snap'in makine öğrenimi mühendisleri tarafından şirket içinde ince ayar yapılan açık kaynaklı bir nesne algılama ve görüntü sınıflandırma modeli kullanılarak geliştirildi. Model, bir görüntüde görünen giyim öğesinin türünü algılar ve ardından bunu, bir moda kataloğunda benzer görünen öğeleri bulmak için benzerlik aramasını kullanan bir moda yerleştirme modeline aktarır.

Screenshop'un yapay zeka hattı başlangıçta makine öğrenimi ve yapay zeka uygulamaları geliştirmek için yaygın olarak kullanılan açık kaynaklı bir çerçeve olan TensorFlow kullanılarak oluşturuldu ve hizmete sunuldu.
Snap'te makine öğrenimi mühendisi Ke Ma, TensorFlow'un erken geliştirme sürecindeki rolünü vurguladı. “Screenshop'un derin öğrenme modelleri başlangıçta TensorFlow kullanılarak geliştirildi” diye açıkladı. “Bu nedenle, bir çıkarım hizmeti platformu seçme zamanı geldiğinde doğal tercihimiz TensorFlow'un yerel hizmet platformu TFServing'i kullanmaktı.”
Çok çerçeveli bir yapay zeka hattının üretim zorluklarını ele alma
Screenshop hizmeti Snapchat'in kullanıcı tabanı arasında ilgi kazandıkça, ML ekibi hizmeti iyileştirmek ve geliştirmek için yollar keşfetmeye başladı. Moda yerleştirme modellerini PyTorch çerçevesine dayalı alternatif bir modelle değiştirerek anlamsal arama sonuçlarının doğruluğunu artırabileceklerini kısa sürede keşfettiler.
Bu durum, yapay zeka modellerini üretim ortamlarında dağıtan kuruluşların karşılaştığı tipik bir zorluğun altını çizdi: Yapay zeka modellerini, her çerçeve için özel çıkarım hizmeti platformlarını yönetmeye, bakımını yapmaya ve dağıtmaya gerek kalmadan farklı arka uç çerçeveleriyle dağıtma ikilemi. Çözüm arayışı Ke Ma ve ekibinin şunu keşfetmesine yol açtı: NVIDIA Triton Çıkarım Sunucusu.
Ke Ma, “Screenshop işlem hattımız için ısmarlama çıkarım hizmeti platformları, TensorFlow için bir TFserving platformu ve PyTorch için bir TorchServe platformu dağıtmak istemedik” diye açıkladı. “Triton'un çerçeveden bağımsız tasarımı ve TensorFlow, PyTorch ve ONNX gibi birden fazla arka uç desteği çok ilgi çekiciydi. Bu, tek bir çıkarım hizmeti platformu kullanarak uçtan uca işlem hattımıza hizmet vermemize olanak tanıdı, bu da çıkarım hizmeti maliyetlerimizi ve üretimdeki modellerimizi güncellemek için gereken geliştirici gün sayısını azalttı.”
Triton Inference Server, üretimde yapay zeka çıkarım iş yüklerinin dağıtımını kolaylaştıran ve hızlandıran açık kaynaklı bir yapay zeka model hizmet platformudur. Kuruluşların, makine öğrenimi geliştiricilerinin ve araştırmacıların model hizmet altyapısının karmaşıklığını azaltmasına, yeni yapay zeka modellerini dağıtmak için gereken süreyi kısaltmasına ve yapay zeka çıkarım ve tahmin kapasitesini artırmasına yardımcı olur. NVIDIA TensorRT, TensorFlow, PyTorch, ONNX, OpenVINO, Python, RAPIDS FIL ve daha fazlasını içeren çok sayıda derin öğrenme ve makine öğrenimi çerçevesini destekler.
NVIDIA Triton Model Toplulukları ve Model Analizörü ile üretime geçiş süresini hızlandırma
Snap'teki ekip, TFServing'ten Triton Inference Server'a geçiş sürecini hızlandırmak için NVIDIA Triton Model Toplulukları ve Model Analizörü özelliklerini başarıyla kullandı.
Faydalanarak Model TopluluklarıAI modellerini tek bir işlem hattına bağlayan kodsuz bir geliştirme aracı olan Screenshop geliştirme ekibi, Python kullanılarak oluşturulan işleme öncesi ve sonrası iş akışlarını herhangi bir kod yazmadan işlem hatlarına entegre etti. Bu onların tek bir çıkarım isteğiyle tüm hattı tetiklemelerine olanak sağladı. Bu, gecikmeyi azalttı ve farklı adımlar arasındaki ileri geri ağ iletişimini en aza indirdi.

Şekil 3, kod yazmadan NVIDIA Triton Model Ensemble kullanılarak ön ve işlem sonrası adımlardan oluşan bir hattın nasıl oluşturulabileceğini göstermektedir.
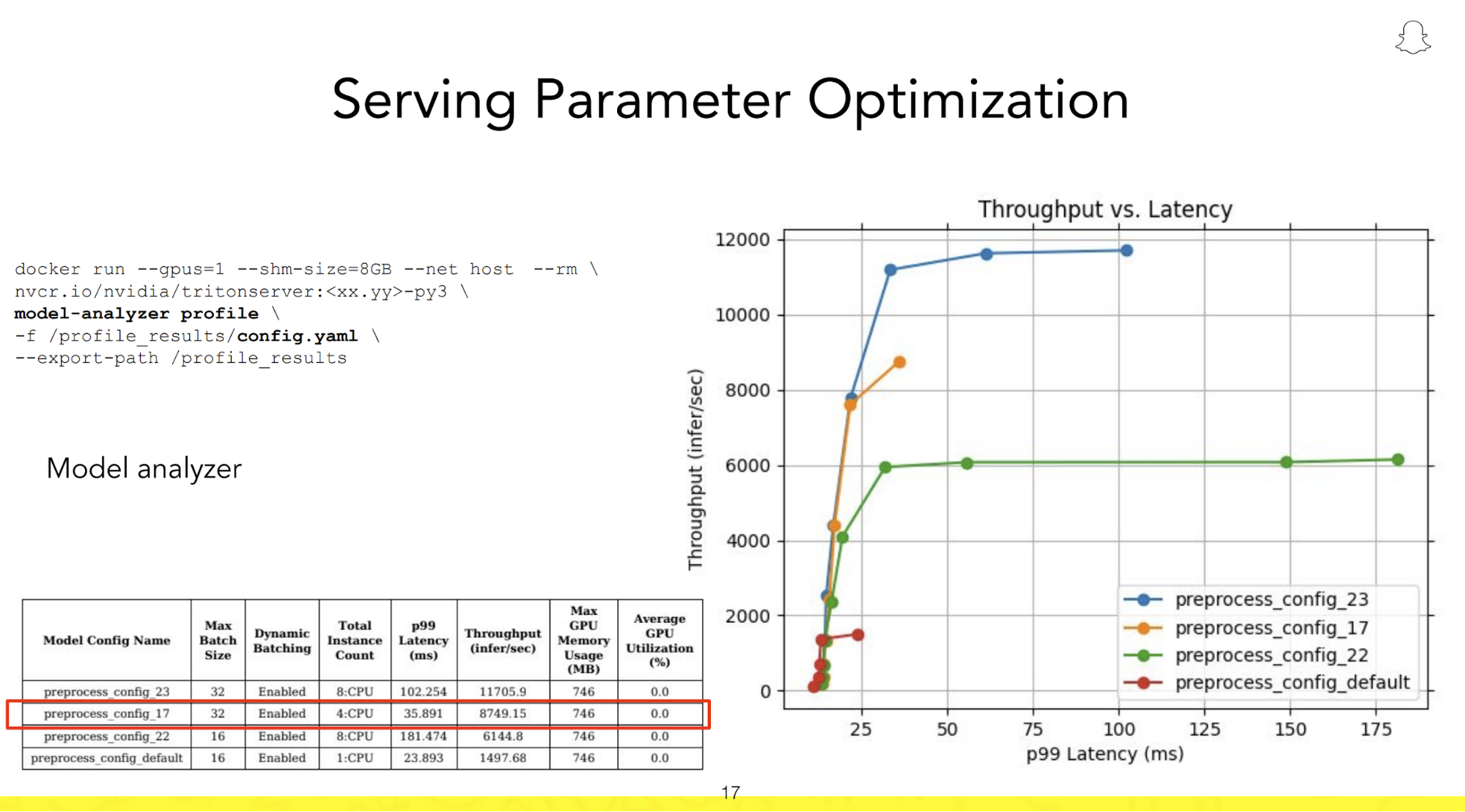
Ekip ayrıca Screenshop işlem hattını çalıştırmak için en iyi yapılandırmayı ve kurulumu hızlı bir şekilde belirlemek ve 100 ms'lik hedef gecikme süresi içinde maksimum verim sağlamak için Triton Inference Server'ın yeteneklerinden de yararlandı.
Öne çıkan bir özelliği Triton Model Analizörü GPU'ya yüklenen eş zamanlı modellerin sayısını ve çıkarım çalıştırma süresi boyunca bir araya getirilen isteklerin sayısını ayarlayarak kullanıcıların çeşitli dağıtım yapılandırmalarıyla denemeler yapmasına olanak tanır. Daha sonra bu konfigürasyonları sezgisel bir grafik üzerinde görsel olarak haritalandırarak üretim kullanımı için en verimli kurulumun hızlı bir şekilde tanımlanmasını ve devreye alınmasını kolaylaştırır.
NVIDIA TensorRT kullanarak verimi 3 kat artırın ve maliyeti %66 azaltın
Screenshop hizmetinin Triton Inference Server'da başarılı bir şekilde başlatılmasının ardından Ke Ma ve ekibi, sistem performansını artırma ve toplam sahip olma maliyetini azaltma konusundaki kararlılığını sürdürdü. Çabaları onları, özellikle NVIDIA GPU'lardaki yapay zeka modelleri için çıkarımı optimize etmeyi amaçlayan bir SDK olan NVIDIA TensorRT'ye yönlendirdi.
Ke Ma, TensorRT'nin temsil etmek için kullanılan bellek bitlerinin sayısını azaltmaya yardımcı olan niceleme özelliklerine atıfta bulunarak, “TensorRT sayesinde, hizmetin kalitesi veya doğruluğu üzerinde herhangi bir etki olmadan modelimizin hassasiyetini FP32'den FP16'ya düşürmeyi başardık” diye açıkladı. model parametreleri.
Screenshop ekibi, derleme süreci sırasında varsayılan NVIDIA TensorRT ayarlarını uyguladı ve %66'lık bir maliyet düşüşü sağlayacağı tahmin edilen iş hacminde hemen 3 kat artışa tanık oldu; bu, hizmete güvenen Snap kullanıcılarının sayısı göz önüne alındığında önemli bir rakam.
Snapchat'in büyüyen kullanıcı tabanını karşılamak için Triton Inference Sunucusunu 1K GPU'lara ölçeklendirme
Screenshop, çıkarım isteklerini verimli bir şekilde işlemek için Triton Inference Server'ı kullanan Snapchat'teki birçok yapay zeka destekli hizmetten yalnızca birini temsil ediyor. Triton Inference Server'ın çok yönlülüğü, özellikle optik karakter tanımaya (OCR) dayananlar olmak üzere çeşitli uygulama ve hizmetleri kapsar.
Snap'te makine öğrenimi mühendisi Byung Eun (Logan) Jeon, “Metinler ve emojiler, 800 milyonu aşan kullanıcı tabanımız arasında yaygın bir iletişim biçimidir” diye açıkladı. GTC'deki son sunum. “Bu metinler ve emojiler, kullanıcıların görsel arama yapmak için paketlenmiş bir ürünün resmini çekmesine olanak tanıyan Güzellik Tarayıcı hizmetimizden içerik denetleme ve politika ihlali tespit hizmetlerimize kadar çok çeşitli hizmetlerimiz için hayati önem taşıyan bağlamsal bilgilerle doludur. .”
Snap kullanıcıları arasında OCR destekli hizmetlere yönelik geniş ve çeşitli talep göz önüne alındığında, etkili bir şekilde ölçeklenebilen bir çıkarım hizmeti platformunun seçilmesi Logan Jeon ve ekibi için çok önemliydi. Triton Inference Server'ın endüstri standardı Kserve protokolüyle uyumluluğu ve Prometheus'u standart HTTP protokolleri üzerinden kullanarak GPU kullanım ölçümlerini izleme ve raporlama yeteneği, ekibin OCR modellerini ölçeklendirmesini kolaylaştırdı. Bunu, Triton Inference Server'ı Kubernetes motorlarına entegre ederek, sunucuyu en üst düzeyde 1K NVIDIA T4 ve L4 GPU'lardan daha fazlasında düzenleyerek verimli hizmet sunumu sağlayarak başardılar.
İş mantığı komut dosyalarıyla Jupiter not defterlerinden üretime zahmetsiz geçiş
Snapchat'in dünya çapında benimsenmesi, OCR ML Mühendislik ekibinin, görüntülere gömülü farklı dillerdeki metinleri doğru bir şekilde işlemek ve yorumlamak için birden fazla dile özgü nesne algılama ve tanıma modelini aynı anda yönetmesini gerektirdi.
OCR'nin araştırma ve geliştirme aşamasında ML ekibi, çıkarım sırasında sunulacak dile özgü uygun modelleri seçmek için özel Python mantığını kullandı. Logan, “Çıkarıma yönelik doğru dile özgü modeli dinamik olarak seçmek için test sırasında Jüpiter not defterlerinde Python koşullu ifadelerini ve döngülerini kullandık” diye açıkladı. “NVIDIA Triton'un BLS özelliği, GPU verimliliğini ve verimi koruyarak bu özel mantığı zahmetsizce üretime geçirmemize olanak sağladı.”
BLS Triton Inference Server'ın özelliği, ML ekibinin özel kodunun Jupiter dizüstü bilgisayarlardan üretime sorunsuz geçişini kolaylaştırdı ve yeni OCR özellikli hizmetlerinin pazara çıkış süresini hızlandırdı. BLS, Triton Inference Server içindeki özel bir komut dosyası oluşturmanıza olanak tanıyan bir dizi yardımcı işlevdir. Bu betik, Python veya C++'da tanımlanan koşullara bağlı olarak Triton Inference Server tarafından barındırılan herhangi bir modeli çağırabilir.
Daha fazla bilgi edin
NVIDIA Triton Çıkarım Sunucusu Ve NVIDIA TensorRT GitHub'da bulunan açık kaynaklı projelerdir. Ayrıca çekilebilen Docker konteynerleri olarak da mevcutturlar. NVIDIA NGC'si ve bir parçasıyız NVIDIA Yapay Zeka KurumsalKurumsal düzeyde güvenlik, kararlılık ve destek sunan.
En kısa sürede değer elde etmek isteyen kuruluşlar, açık kaynak topluluğu ve NVIDIA AI Foundation modelleri de dahil olmak üzere çok çeşitli AI modellerinde hızlandırılmış çıkarım için bir dizi kullanımı kolay mikro hizmet olan NVIDIA NIM'i kullanabilir.