

Öneri sistemleri, çeşitli platformlarda kullanıcı deneyimlerini kişiselleştirmede önemli bir rol oynar. Bu sistemler, kullanıcıların geçmiş davranışlarına ve tercihlerine dayanarak etkileşime girme olasılığı yüksek olan öğeleri tahmin etmek ve önermek için tasarlanmıştır. Etkili bir öneri sistemi oluşturmak, kullanıcılar ve öğeler arasındaki etkileşimleri yakalayan büyük, karmaşık veri kümelerini anlamayı ve bunlardan yararlanmayı içerir.
Bu gönderi size ortak ziyaret matrislerine dayalı basit ama güçlü bir öneri sisteminin nasıl oluşturulacağını gösterecektir. Ortak ziyaret matrisleri oluşturmadaki temel zorluklardan biri, büyük veri kümelerini işlemede yer alan hesaplama karmaşıklığıdır. Kütüphaneler kullanan geleneksel yöntemler pandalar özellikle milyonlarca hatta milyarlarca etkileşimle uğraşırken verimsiz ve yavaş olabilir. İşte tam da bu noktada RAPDIS cuDF RAPIDS cuDF, verileri yüklemek, filtrelemek ve düzenlemek için pandas benzeri bir API sağlayan bir GPU DataFrame kütüphanesidir.
Öneri sistemleri ve eş ziyaret matrisleri
Öneri sistemleri, kullanıcılara kişiselleştirilmiş öneriler veya tavsiyeler sunmayı amaçlayan bir makine öğrenimi algoritmaları kategorisidir. Bu sistemler, e-ticaret (Amazon, OTTO), içerik akışı (Netflix, Spotify), sosyal medya (Instagram, X, TikTok) ve daha fazlası dahil olmak üzere çeşitli uygulamalarda kullanılır. Bu sistemlerin rolü, kullanıcıların ilgi alanları ve tercihleriyle uyumlu ürünleri, hizmetleri veya diğer içerikleri keşfetmelerine yardımcı olmaktır.
Bir öneri sistemi oluşturmak için kullanılan veri kümeleri genellikle şunları içerir:
tavsiye edilecek ürünler.
çok büyük (hatta milyonlarca) olabilir.
- Kullanıcılar ve öğeler arasındaki etkileşimler. Belirli bir kullanıcı için bu tür etkileşimlerin dizisine bir etkileşim denir. oturumAmaç, kullanıcının bir sonraki etkileşimde hangi öğelerle karşılaşacağını çıkarsamaktır.
Şekil 1, kullanıcının 6543, 242, 5381 ve 5391 numaralı öğelerle etkileşime girdiği bir örnek oturumu göstermektedir. Öneri sisteminin amacı, kullanıcının daha sonra hangi öğelerle etkileşime gireceğini tahmin etmektir. Performansı değerlendirmenin yaygın bir yolu, Geri Çağırma özelliğini kullanmaktır 

Bir oturum sırasında, bir kullanıcı genellikle birkaç öğeyle etkileşime girer. ortak ziyaret matrisi Birlikte görünen öğeleri sayar ve boyuta sahiptir 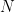
Ortak ziyaret matrisleri oluşturmanın zorlukları
Ortak ziyaret matrislerini hesaplamak, tüm oturumlara bakmayı ve tüm eş zamanlı oluşumları saymayı gerektirir. Bu hızla maliyetli hale gelir: belirli büyüklükteki bir oturum için 

pandas hesaplamaları uygulamayı kolaylaştırır, ancak verimlilik pahasına. Bir yandan, hafızanın patlamaması için oturumların parçalara ayrılması gerekir. Öte yandan, büyük veri kümeleri önemli yavaşlamalara neden olur.
Pandas’ın kod netliğine de izin veren daha hızlı bir hesaplama çerçevesi gereklidir. RAPIDS cuDF’nin devreye girdiği yer burasıdır. RAPIDS cuDF’yi kullanarak sıfır kod değişikliğiyle hesaplamaları 40 kat hızlandırabilirsiniz.
Bu gönderi, ortak ziyaret matrisinin nasıl oluşturulacağını ve iş akışının nasıl hızlandırılacağını göstermektedir. RAPIDS cuDF pandas hızlandırıcı modu. Okurken kodu çalıştırmak, hızlandırıcının gerçekte ne kadar yararlı olduğunu daha iyi anlamanızı sağlayacaktır. Başlamadan önce, GPU hızlandırıcısını açtığınızdan emin olun. Daha fazla ayrıntı için, demo not defterine bakın.
RAPIDS cuDF pandas hızlandırıcı modu
RAPIDS cuDF, büyük veri kümeleri üzerinde CPU’da gerçekleştirildiğinde yavaş olabilen işlemleri (örneğin yükleme, birleştirme, toplama ve filtreleme) hızlandırmak için tasarlanmış bir Python GPU DataFrame kütüphanesidir.
API stili pandas’a benzer ve yeni cuDF pandas hızlandırıcı moduyla, herhangi bir kod değişikliği yapmadan pandas iş akışlarınıza hızlandırılmış bilgi işlem getirebilirsiniz. cuDF kitaplığı, tablo veri işleme için 50x ila 150x daha hızlı performans sunar.
RAPIDS cuDF pandas hızlandırıcı modu, cuDF kütüphanesinin kapasitesini genişletir ve tablo veri işleme için 50 kat ila 150 kat daha hızlı performans sunar. Herhangi bir kod değişikliği gerektirmeden pandas iş akışlarınıza hızlandırılmış bilgi işlem getirmenizi sağlar.
Veriler
Bu eğitimde kullanılan veriler, eğitim setinden çıkarılmıştır. OTTO – Çok Amaçlı Öneri Sistemi Bir aylık oturumlar içeren Kaggle yarışması. İlk üç hafta matrisleri oluşturmak için, son hafta ise değerlendirme için kullanılır. Doğrulama oturumları model için hedefler oluşturmak amacıyla kısaltılmıştır. Recall@20, eş-ziyaret matrislerinin kısaltılmış öğeleri ne kadar iyi geri getirebildiğini görmek için kullanılacaktır.
Bilgi sızıntısını önlemek için zamansal bir bölme kullanmanın önemli olduğunu unutmayın. Test verileri, veri setinin beşinci haftasını içerir. Veri seti 1,86 milyon öğe ve bu öğelerle yaklaşık 500 milyon kullanıcı etkileşimi içerir. Bu etkileşimler, daha kolay kullanım için parçalı parke dosyalarında saklanır.
Veriler hakkında şu bilgiler bilinmektedir:
session: Oturum kimliği; bu durumda bir oturum bir kullanıcıya eşdeğerdiraid: Öğe kimliğits: Etkileşimin gerçekleştiği zamantype: Etkileşim türü; tıklamalar, sepetler veya siparişler olabilir

Ortak ziyaret matrislerinin uygulanması
Veri kümesindeki öğe sayısı nedeniyle bellek bir sorundur. Bu nedenle, eş-ziyaret matrisinin çok büyük olmasını önlemek için verileri iki parçaya bölün. Ardından eğitim verilerindeki tüm parquet dosyaları üzerinde döngü yapın.
covisitation_matrix = []
for part in range(PARTS):
print(f"- Part {part + 1}/{PARTS}")
matrix = None
for file_idx, file in enumerate(tqdm(train_files)):
İlk adım verileri yüklemektir. Ardından hafızayı korumak için bazı dönüşümler uygulayın: sütunların türlerini değiştirin int32ve 30 etkileşimden uzun oturumları sınırlayın.
for part in range(PARTS):
for file_idx, file in enumerate(tqdm(train_files)):
[...]
# Load sessions & convert columns to save memory
df = pd.read_parquet(file, columns=["session", "aid", "ts"])
df["ts"] = (df["ts"] / 1000).astype("int32")
df[["session", "aid"]] = df[["session", "aid"]].astype("int32")
# Restrict to first 30 interactions
df = df.sort_values(
["session", "ts"],
ascending=[True, False],
ignore_index=True
)
df["n"] = df.groupby("session").cumcount()
df = df.loc[df.n < 30].drop("n", axis=1)
Sonra, verileri oturum sütununda kendisiyle toplayarak tüm eş oluşumları elde edebilirsiniz. Bu zaten zaman alıcıdır ve ortaya çıkan veri çerçevesi oldukça büyüktür.
# Compute pairs
df = df.merge(df, on="session")
Matris hesaplamasının maliyetini azaltmak için, öğeleri şu anda dikkate alınan parçadaki öğelerle sınırlayın. Ayrıca yalnızca 1 saat içinde farklı öğelerde gerçekleşen etkileşimleri dikkate alın. Oturumlar içinde yinelenen etkileşimlere izin vermeyin.
# Split in parts to reduce memory usage
df = df.loc[
(df["aid_x"] >= part * SIZE) &
(df["aid_x"] < (part + 1) * SIZE)
]
# Restrict to same day and remove self-matches
df = df.loc[
((df["ts_x"] - df["ts_y"]).abs() < 60 * 60) &
(df.aid_x != df.aid_y)
]
# No duplicated interactions within sessions
df = df.drop_duplicates(
subset=["session", "aid_x", "aid_y"],
keep="first",
).reset_index(drop=True)
Bir sonraki adımda, matris ağırlıklarını hesaplayın. Çiftler üzerinde bir toplam toplama yaparak tüm birliktelikleri sayın.
# Compute weights of pairs
df["wgt"] = 1
df["wgt"] = df["wgt"].astype("float32")
df.drop(["session", "ts_x", "ts_y"], axis=1, inplace=True)
df = df.groupby(["aid_x", "aid_y"]).sum()
İkinci döngünün sonunda (parquet dosyaları üzerinde dönen döngü), yeni hesaplanan ağırlıkları öncekilere ekleyerek katsayıları güncelleyin. Ortak ziyaret matrisleri büyük olduğundan, bu işlem yavaştır ve belleği tüketir. Biraz bellek boşaltmak için kullanılmayan değişkenleri silin.
# Update covisitation matrix with new weights
if matrix is None:
matrix = df
else: # this is the bottleneck operation
matrix = matrix.add(df, fill_value=0)
# Clear memory
del df
gc.collect()
Tüm verileri gördükten sonra, yalnızca matrisleri tutarak matrislerin boyutunu küçültün. N öğe başına en iyi adaylar—yani en yüksek ağırlığa sahip adaylar. İlginç bilgiler burada bulunur.
for part in range(PARTS):
[...]
# Final matrix : Sort values
matrix = matrix.reset_index().rename(
columns={"aid_x": "aid", "aid_y": "candidate"}
)
matrix = matrix.sort_values(
["aid", "wgt"], ascending=[True, False], ignore_index=True
)
# Restrict to n candids
matrix["rank"] = matrix.groupby("aid").candidate.cumcount()
matrix = matrix[matrix["rank"] < N_CANDIDS].reset_index(drop=True)
covisitation_matrix.append(matrix)
Son adım, ayrı ayrı hesaplanan matrisin farklı bölümlerini birleştirmektir. Daha sonra, gerekirse matrisinizi diske kaydetmeyi seçebilirsiniz.
covisitation_matrix = pd.concat(covisitation_matrix, ignore_index=True)
İşte karşınızda. Bu kod, pandas kullanarak basit bir ortak ziyaret matrisi hesaplar. Tek bir büyük kusuru vardır: yavaştır, matrisi hesaplamak neredeyse 10 dakika sürer! Ayrıca makul bir çalışma süresi için verileri önemli ölçüde kısıtlamayı gerektirir.
cuDF pandas hızlandırıcı modu
Ve cuDF pandas hızlandırıcı modu tam da burada devreye giriyor. Çekirdeği yeniden başlatın ve tek bir kod satırıyla GPU’nuzun gücünü serbest bırakın:
Tablo 1 cuDF hızlandırmalı ve hızlandırmasız çalışma sürelerini gösterir. Bir satır kod 40 kat hızlanma sağlar.
| pandalar | cuDF pandaları | |
| Verilerin %10’u | 8 dk 41 sn | 13 saniye |
| Tüm veri seti | 1 saat 30 dakika+ | 5 dk 30 sn |
Aday oluşturma
Tavsiye edilecek adaylar üretmek, ortak ziyaret matrislerinin bir kullanımıdır. Bu, ortak ziyaret matrisinin ağırlıklarının bir oturumdaki tüm öğeler üzerinde toplanmasıyla yapılır. En yüksek ağırlığa sahip öğeler tavsiye edilecektir. Uygulama pandas’ta basittir ve bir kez daha GPU hızlandırıcısından faydalanır.
Verileri yükleyerek başlayın, sonra yalnızca sonuncusunu düşünün N_CANDIDS görülen öğeler. Oturumlarda daha önce görülen öğeler harika önerilerdir. Önce bunlar önerilecektir. Hafızayı korumak için kendi kendine eşleşmelerin ortak ziyaret matrislerinden kaldırıldığını unutmayın, bu yüzden bunları burada geri yükleyin.
candidates_df_list = []
last_seen_items_list = []
for file_idx in tqdm(range(len(val_files))):
# Load sessions & convert columns to save memory
df = pd.read_parquet(
val_files[file_idx], columns=["session", "aid", "ts"]
)
df["ts"] = (df["ts"] / 1000).astype("int32")
df[["session", "aid"]] = df[["session", "aid"]].astype("int32")
# Last seen items
df = df.sort_values(
["session", "ts"], ascending=[True, False], ignore_index=True
)
df["n"] = df.groupby("session").cumcount()
# Restrict to n items
last_seen_items_list.append(
df.loc[df.n < N_CANDIDS].drop(["ts", "n"], axis=1)
)
df.drop(["ts", "n"], axis=1, inplace=True)
Sonra, oturumdaki öğelerdeki ortak ziyaret matrisini birleştirin. Oturumdaki her öğe daha sonra şu öğelerle ilişkilendirilir: N_CANDIDS En yüksek ağırlığa sahip adayları tavsiye sistemine dahil edebilirsiniz.
for file_idx in tqdm(range(len(val_files))):
[...]
# Merge covisitation matrix
df = df.merge(
covisitation_matrix.drop("rank", axis=1), how="left", on="aid"
)
df = df.drop("aid", axis=1).groupby(
["session", "candidate"]
).sum().reset_index()
# Sort candidates
df = df.sort_values(["session", "wgt"], ascending=[True, False])
# Restrict to n items
df["rank"] = df.groupby("session").candidate.cumcount()
df = df[df["rank"] < N_CANDIDS].reset_index(drop=True)
candidates_df_list.append(df)
Performans değerlendirmesi
Adayların gücünü değerlendirmek için geri çağırma metriğini kullanın. Geri çağırma, geri çağırıcı tarafından başarılı bir şekilde bulunan yer gerçeğindeki öğelerin oranını ölçer.
Bu durumda, 20 adaya izin verin. Kullanıcıların satın aldığı öğelerin matrislerin başarıyla geri aldığı oranını görmek istiyorsunuz. Elde edilen geri çağırma 0,5868’dir, bu zaten güçlü bir temel değerdir. Tavsiye eden tarafından döndürülen 20 öğeden ortalama 11’i kullanıcı tarafından satın alındı. Bu zaten güçlü bir temel değerdir: yarışma sırasında, en iyi takımlar 0,7’ye yakın puanlara ulaştı. demo not defteri Uygulamaya ilişkin ayrıntılar bu yazının kapsamı dışındadır.
Daha da ileri gitmek
Ortak ziyaret matrisi hesaplamasını ve toplamasını hızlandırmak, aday hatırlamayı iyileştirmek için çok hızlı yineleme yapmanızı sağlar. İlk iyileştirme, matrislere daha fazla geçmiş vermektir. Hızlı bir uygulama ile bu, hesaplamaların bitmesini saatlerce beklemeden yapılabilir.
Ardından matrisleri iyileştirin. Çeşitli yaklaşımları deneyebilmenize rağmen, şimdilik, eş-ziyaret matrislerine eş zamanlı olarak ortaya çıkan her öğe için bir ağırlık veriliyor. Demo, zaman açısından daha yakın olan öğelere daha fazla ağırlık veriyor, çünkü bu tür etkileşimler daha alakalı görünüyor. Bir diğer fikir de etkileşim türünü göz önünde bulundurmak. Birlikte satın alınan öğeler veya birlikte sepete eklenen öğeler, yalnızca görüntülenen öğelerden daha çok tavsiye edilebilir görünüyor.
Şimdiye kadar, matris ağırlıkları toplanırken oturumdaki tüm öğeler eşit derecede önemli kabul edildi. Oturumda daha sonra görünen öğeler, en eski olanlardan daha fazla öngörücü faktöre sahiptir. Bu nedenle, oturumun sonuna yaklaştıkça öğelerin adaylarının ağırlıklarını artırarak toplamayı iyileştirmek mümkündür.
Bu üç değişikliği kullanarak, recall@20 0,5992’ye iyileşir. Uygulamalar, bu gönderide sunulan kodla aynı şemayı izler, iyileştirmeleri getirmek için birkaç satır eklenir. Ayrıntılar için bkz. demo not defteri.
Son adım, farklı aday tiplerini yakalamak için birden fazla eş-ziyaret matrisini birleştirmektir.
Özet
Bu gönderi, ortak ziyaret matrisleri oluşturma ve optimize etme konusunda kapsamlı bir kılavuz sunar. Ortak ziyaret matrisleri basit bir araç olsa da (kullanıcı oturumları sırasında öğelerin ortak oluşumunu sayarlar), bunları oluşturmak büyük miktarda veri işlemeyi içerir. Bunu verimli bir şekilde yapmak, hızlı bir şekilde yinelemek ve öneri sistemlerini iyileştirmek için gereklidir.
RAPIDS cuDF ve yeni yayınlanan pandas hızlandırıcı modundan yararlanılarak, ortak ziyaret matrisi hesaplaması 50 kata kadar daha hızlıdır. GPU hızlandırma sayesinde çeşitli ortak ziyaret matrisleri setini hızla oluşturmak, NVIDIA’nın Kaggle Grandmasters’ının KDDCup 2023 ve OTTO dahil olmak üzere birden fazla öneri sistemi yarışmasını kazanmasını sağlayan önemli bir bileşendi.
Bu arada demo not defteri sadece iki tip matris hesaplar, olasılıklar sınırsızdır. Kodla denemeler yapın ve farklı adayları yakalamak için matrislerin yapısını iyileştirmeye çalışın.